Implementing a Serverless Architecture
Event-driven serverless architectures promise improved resiliency and scalability, as serverless platforms consist of managed services that abstract away the infrastructure used to operate them. Serverless also promises increased agility because we can focus on building and delivering new capabilities quickly, without needing to work with the infrastructure.
In the previous article we discussed how to design an application architecture to effectively leverage serverless, and showed a simple example (based on the “Build a serverless web app in Azure” tutorial). In this article we discuss how that architecture can be made highly available and fault-tolerant across multiple data center regions in Azure, as well as enabling continuous deployment, operations automation, and monitoring, etc.; just as real applications do.
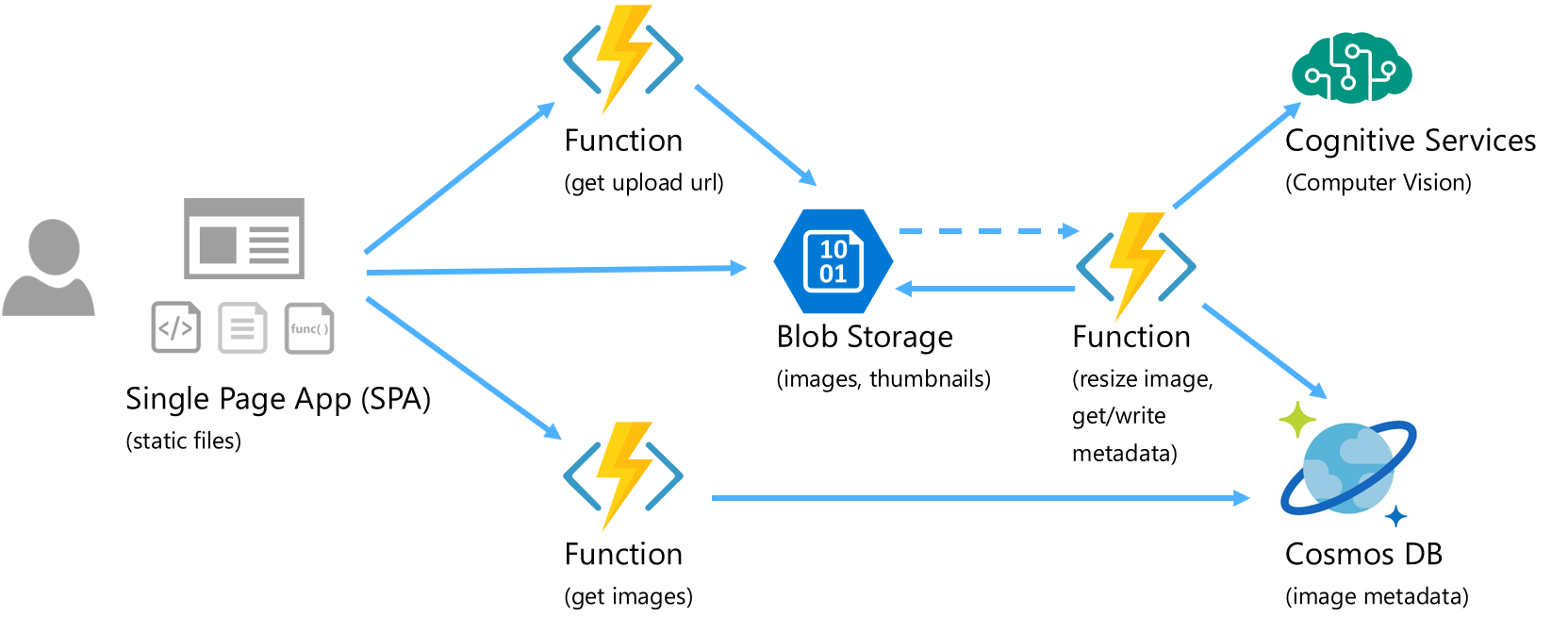
Application Architecture
This app allows users to upload images, then resizes it into a thumbnail image, calls the Computer Vision API in Cognitive Services to recognize its contents, and saves the metadata. The architecture is simple functionality-wise, though it has many typical and necessary elements of a real web application, and all implemented entirely in a serverless model.
- Web Server – Blob Storage (GPv2) with the static website hosting feature is used to serve the HTML, CSS, and JavaScript files that make up the client application (single page app (SPA)). This is neat because we’re not using a persistent server process running 24/7 in a VM instance listening on a port waiting for client requests from a browser. All static files are served from Blob Storage directly
- Application Service API’s – the web app interacts with service API’s to access cloud-based functionalities, implemented as Function apps (in this case written using Node.js):
- GetImages – this is the frontend API for the client app to get a list of available images and their metadata from Cosmos DB
- GetUploadUrl – when a user wants to upload an image file, the client app calls this Function app via an HTTP trigger, which requests a shared access signature (SAS) token from Blob Storage and sends it back to the client app, to upload the image file directly into Blob Storage
- ResizeImage – this is the backend worker process that gets triggered by Blob Storage when a new image file is uploaded into Blob Storage; it resizes the image into a thumbnail, saves it into Blob Storage, calls Cognitive Services to recognize the image, then saves the metadata into Cosmos DB
- Database – Cosmos DB
- File Storage – Blob Storage
The end-to-end architecture is serverless – that is, when idle (no users), no compute processes are allocated and running to wait for user input. The only resources that would incur charges when idle are the data and files in database and storage; compute resources would only incur charges when there are requests sent from client apps. The only one exception being the Request Unit throughput level allocation in Cosmos DB which has a time-based factor in its billing meter.
The architecture at this point is also highly resilient and highly scalable (from 0 to many users) without needing any configuration for auto-scaling or instances across fault domains; it’s all built-in to the services used. The only exception is the Request Unit throughput level allocation in Cosmos DB, which requires adjustment if more throughput is needed to accommodate significant changes in transaction volume (this can be automated too; we’d need to build some functionality to monitor the metrics and interact with Cosmos DB’s service API’s based on how the application should behave).
Resource Provisioning
The provisioning and configuration of various resources in a region can be scripted to help minimize errors, and provision additional sets of resources consistently. In this implementation, a Bash script invoking the Azure CLI 2.0 (command-line interface) is used, instead of the JSON-based ARM (Azure Resource Manager) templates. Shell scripting environments provide a lot of useful utilities, and CLI 2.0 has many rich features such as JMESPath queries, so the resulting scripts are pretty much infrastructure-as-code, which is pretty neat. Plus, with a personal bias towards Unix shell scripting, and now being able to run Bash scripts with the Windows Subsystem for Linux in Windows 10, or with the Cloud Shell in Azure Portal, provides a lot of flexibility to automate resource provisioning and management.
Below is the Azure CLI Bash script used for provisioning resources used for this application architecture.
#!/bin/bash
# Set variables
resourceGroupName='<Azure Resource Group name>'
location='<Azure region name>'
accountName='<Location-specific Blob Storage account name>'
compVisionName='<Location-specific Cognitive Services account name>'
functionName='<Location-specific Function account name>'
functionStorageName='<Location-specific Storage account name used for Function apps>'
cosmosName='<Cosmos DB account name>'
databaseName='<Cosmos DB database name>'
githubUrl='<Github repo URL>'
# Resource group
az group create -n $resourceGroupName -l $location
# Blob Storage
az storage account create -n $functionStorageName -g $resourceGroupName \
--kind StorageV2 -l $location \
--https-only true \
--sku Standard_GRS
az storage account create -n $accountName -g $resourceGroupName \
--kind StorageV2 -l $location \
--https-only true \
--sku Standard_RAGRS
az storage container create -n images \
--account-name $accountName \
--public-access blob
az storage container create -n thumbnails \
--account-name $accountName \
--public-access blob
blobConnection=$(az storage account show-connection-string \
-n $accountName -g $resourceGroupName \
--query "connectionString" \
--output tsv)
az storage cors add \
--methods OPTIONS PUT \
--origins '*' \
--exposed-headers '*' \
--allowed-headers '*' \
--services b \
--account-name $accountName
blobBaseUrl=$(az storage account show \
-n $accountName -g $resourceGroupName \
--query primaryEndpoints.blob -o tsv | sed 's/\/$//')
webBaseUrl=$(az storage account show \
-n $accountName -g $resourceGroupName \
--query primaryEndpoints.web -o tsv | sed 's/\/$//')
# Cosmos DB
az cosmosdb create -g $resourceGroupName -n $cosmosName \
--enable-multiple-write-locations true
az cosmosdb database create -g $resourceGroupName -n $cosmosName \
--db-name $databaseName
az cosmosdb collection create -g $resourceGroupName -n $cosmosName \
--db-name $databaseName \
--collection-name images \
--throughput 400
# Cognitive Services
az cognitiveservices account create -g $resourceGroupName -n $compVisionName \
--kind ComputerVision \
--sku S1 \
-l $location
compVisionKey=$(az cognitiveservices account keys list \
-g $resourceGroupName -n $compVisionName \
--query key1 --output tsv)
compVisionUrl=$(az cognitiveservices account show \
-g $resourceGroupName -n $compVisionName \
--query endpoint --output tsv)
# Function
az functionapp create -n $functionName -g $resourceGroupName \
-s $functionStorageName -c $location
az functionapp cors add -g $resourceGroupName -n $functionName \
--allowed-origins $webBaseUrl
az functionapp config appsettings set -n $functionName -g $resourceGroupName \
--settings AZURE_STORAGE_CONNECTION_STRING=$blobConnection -o table
az functionapp config appsettings set -n $functionName -g $resourceGroupName \
--settings COMP_VISION_KEY=$compVisionKey COMP_VISION_URL=$compVisionUrl \
-o table
az functionapp config appsettings set --n $functionName -g $resourceGroupName \
--settings FUNCTIONS_EXTENSION_VERSION=~1
az functionapp deployment source config -n $functionName -g $resourceGroupName \
--repo-url $githubUrl \
--branch master \
--repository-type github
az functionapp deployment source sync -n $functionName -g $resourceGroupName
functionUrl="https://"$(az functionapp show \
-n $functionName -g $resourceGroupName \
--query "defaultHostName" \
--output tsv)
# Update Settings in client app
echo "window.apiBaseUrl = '$functionUrl'" > settings.js
echo "window.blobBaseUrl = '$blobBaseUrl'" >> settings.js
az storage blob upload -c \$web \
--account-name $accountName \
-f settings.js \
-n settings.js
As shown, most of the required resources can be provisioned and configured using Azure CLI 2.0, including retrieving connection strings, account keys etc. and setting them as configuration values for other resources, setting CORS (cross-origin resource sharing) rules, etc. However, even though CLI 2.0 (v2.0.49) at the time of this writing supports most of the resources we’d want to use, there are still a few resources that are missing, such as setting up diagnostic logging which is supported via CLI 1.0 (e.g., with the azure insights diagnostic command). So there are still a few steps that need to done separately.
As a result, the resource group that hosts this application looks like this:
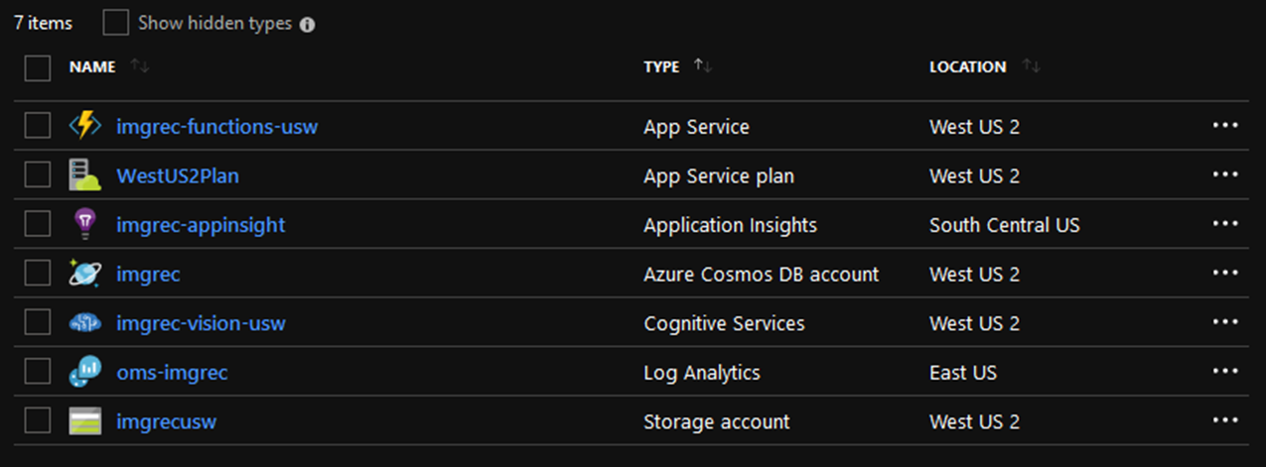
Configuration Management
Another neat thing in this architecture is that environment configurations are abstracted from the code, leveraging the triggers and bindings feature in Azure Functions. This means that the application code and configurations don’t have to be modified between environments, such as when setting up production, QA, staging, development, etc. environments. The connection strings, account keys, etc. for the resources a Function needs to work with, can be set up during resource provisioning time. In this case, this is done via the few lines of az functionapp config appsettings set commands in the resource provisioning Bash script above, which sets the information from the provisioned Blob Storage and Cognitive Services resources into application settings for the Function apps as environment variables, which then gets used by the Functions host.
For example, taking a look at the most simple Function app in this implementation, the GetImages HTTP service API. Here is the application code (JavaScript on Node.js) used in the Function app in index.js, which doesn’t do anything other than receiving the request, then setting the output documents to the response:
module.exports = function (context, req, documents) {
context.res = documents;
context.done();
};
And the trigger and binding configuration in function.json:
{
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req"
},
{
"type": "http",
"direction": "out",
"name": "res"
},
{
"type": "documentDB",
"name": "documents",
"databaseName": "imagesdb",
"collectionName": "images",
"sqlQuery": "select * from c order by c._ts desc",
"connection": "imgrec_DOCUMENTDB",
"direction": "in"
}
],
"disabled": false
}
As shown, GetImages uses the HTTP trigger so it can be called from the client app, and provides a response via HTTP. The work it does to query Cosmos DB to get a list of images is all in configuration in function.json – the database and collection names, the SQL query to execute, and the connection which is provided by Azure (as long as we name the Cosmos DB account “imgrec” in this case).
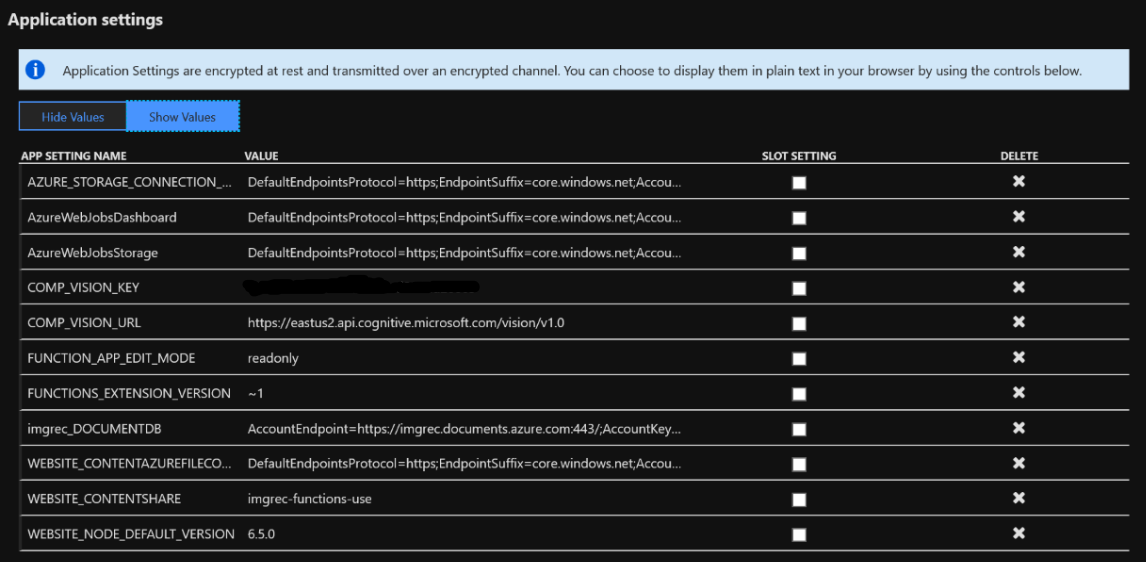
And below is a screenshot of the application settings tab for the Function app.
As well as the function.json configuration for the ResizeImages function, where we can see how the connection string for Blob Storage is accessed by ResizeImages.
{
"bindings": [
{
"name": "myBlob",
"type": "blobTrigger",
"direction": "in",
"path": "images/{name}",
"connection": "AZURE_STORAGE_CONNECTION_STRING",
"dataType": "binary"
},
{
"type": "blob",
"name": "thumbnail",
"path": "thumbnails/{name}",
"connection": "AZURE_STORAGE_CONNECTION_STRING",
"direction": "out"
},
{
"type": "documentDB",
"name": "$return",
"databaseName": "imagesdb",
"collectionName": "images",
"createIfNotExists": false,
"connection": "imgrec_DOCUMENTDB",
"direction": "out"
}
],
"disabled": false
}
And the code snippet in ResizeImage’s index.js to call the Computer Vision API in Cognitive Services, where it accesses the environment variable directly via process.env.COMP_VISION_URL and process.env.COMP_VISION_KEY:
axios.post(process.env.COMP_VISION_URL + '/vision/v1.0/analyze?visualFeatures=Description&language=en', myBlob, {
headers: {
'Ocp-Apim-Subscription-Key': process.env.COMP_VISION_KEY,
'Content-Type': 'application/octet-stream'
}
One thing to point out, at the time of this writing, Azure CLI returns the Computer Vision API URL as “
The ability to abstract environment configuration details from code is key to enabling a consistent resource provisioning and configuration process when managing the architecture that has multiple environments, and/or spans multiple physical regions.
Continuous Deployment
The Azure CLI Bash script helps to provision resources consistently across environments and to correctly set configuration, but the application code and assets for the Function apps should also use automation to ensure a consistent deployment, especially from an ongoing maintenance perspective, and as the number of environments grow.
We simply use the built-in continuous deployment support in Azure Functions. In this case Github is used (among a number of integrations Azure Functions provide out-of-the-box), and is implemented as part of the Azure CLI Bash script when provisioning resources, using the az functionapp deployment source config command to set up, then az functionapp deployment source sync to synchronize from the repository.
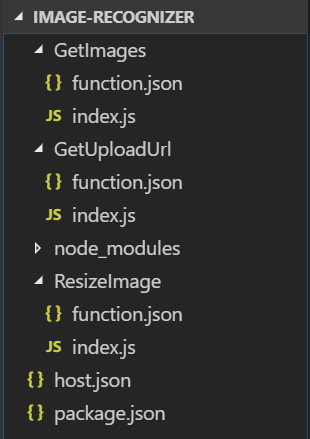
For example, this is the project structure for this application that is uploaded to Github (though there are +100 folders and thousands of files in node_modules):
Below is a screenshot of the Deployment Center in a Function app instance, with some additional details that show the status and log of a repository synchronization process.
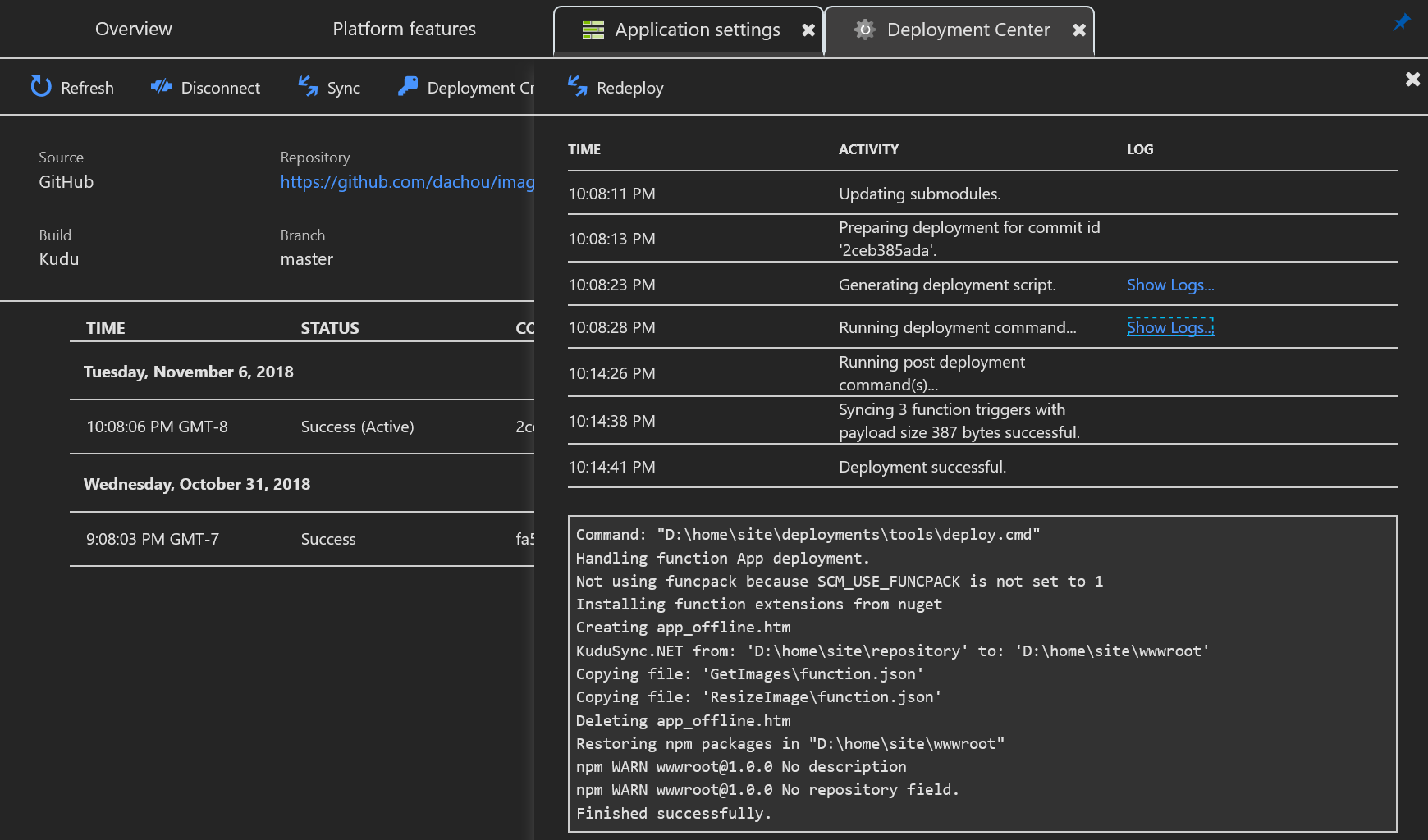
In the Azure CLI Bash script the sync command is called just to ensure a repository synchronization is done. However, that isn’t necessary from an ongoing basis because automated synchronization is also enabled so that changes are synchronized whenever they are committed to the designated branch in Github. As a result, we can manage the updates to the appliation code in multiple environments via Github. And from that perspective, we can also add in Azure DevOps for more development process management capabilities.
Multi-Region Deployment
Having the application highly available in one region is a good start, but it’d be even better if the application works across multiple regions (in this case, “West US 2” (Washington) and “East US 2” (Virginia) regions in Azure), expanding the footprint of the architecture to accommodate more users closer to their physical locations. And, be able to operate seamlessly in the unlikely event of region failures, without impacting users.
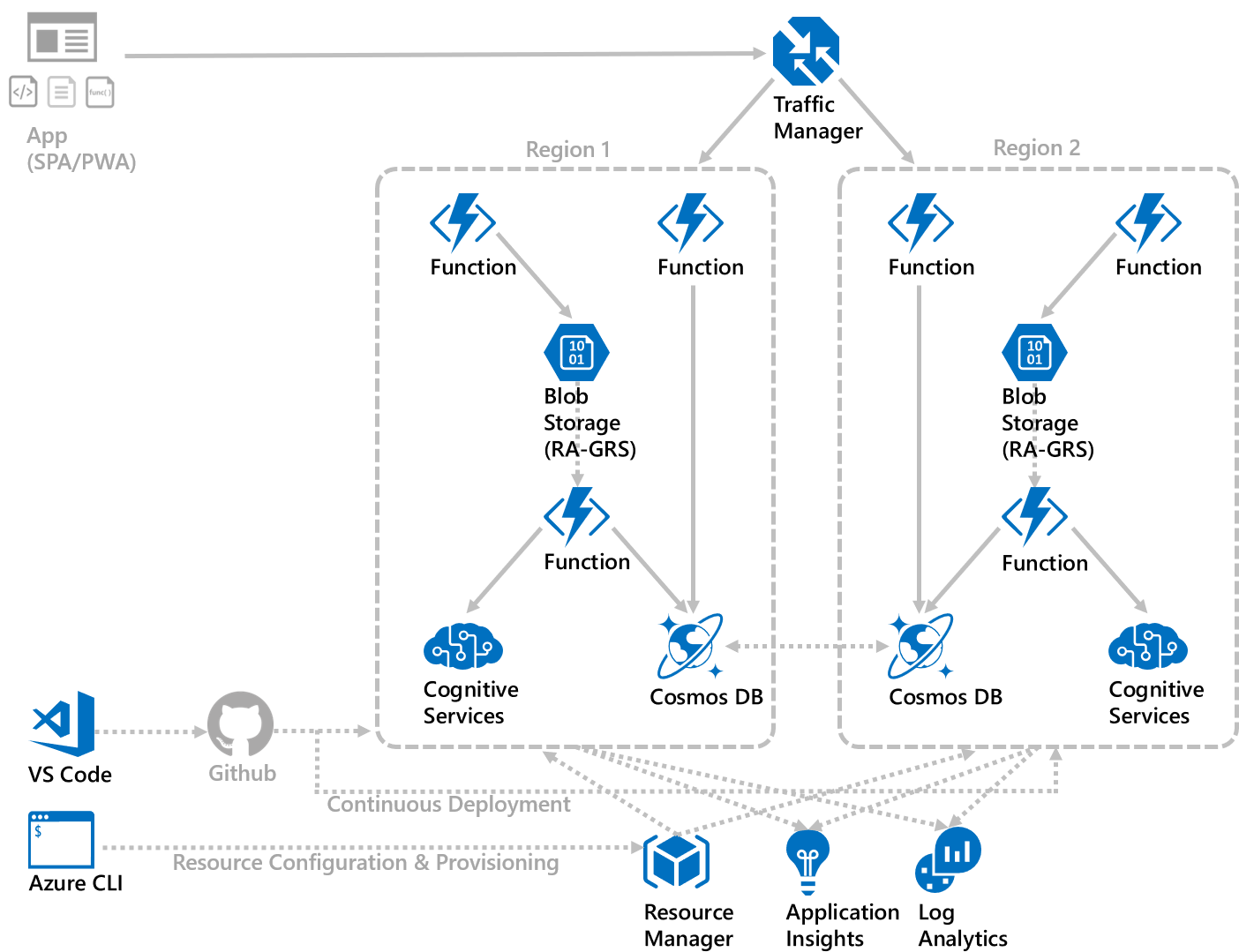
To implement this, a few additional changes are needed.
Traffic Manager – created a Traffic Manager profile to serve as the top-level DNS name for the service API’s hosted Azure Functions in each Azure Region. The client app only needs to interact with this DNS name, such as “imgrec.trafficmanager.net”, instead of the actual end points hosted in each Azure region (e.g., imgrec-functions-usw.azurewebsites.net for the one in West US 2, and imgrec-functions-use.azurewebsites.net for the one in East US 2).
As a result, we can access the service API’s via the Traffic Manager end point, as shown in the screenshot below from Postman:
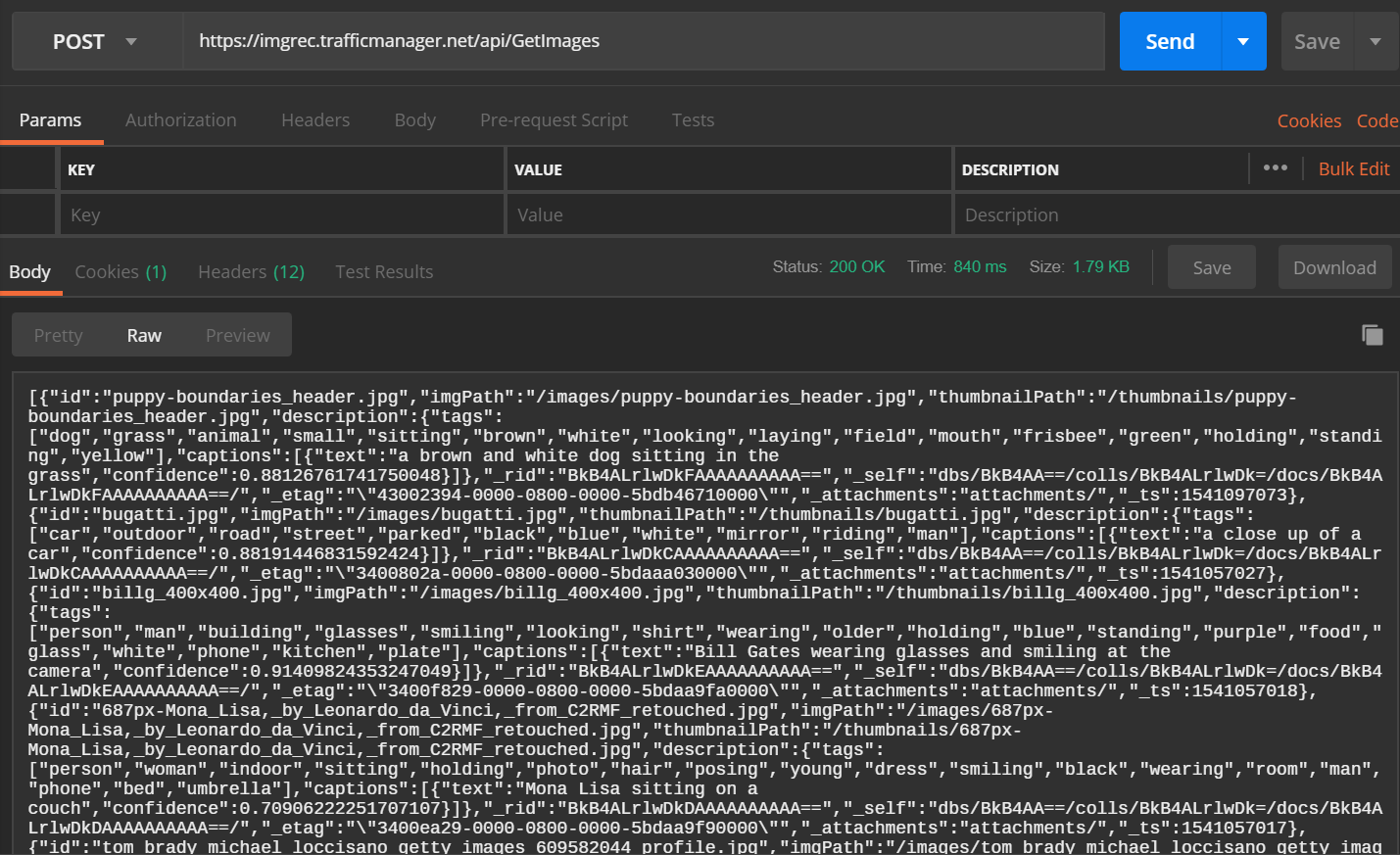
And to accommodate CORS requirements from the client app in the browser issuing HTTP requests to service API’s, we need to provide a CNAME for the Traffic Manager and Function end point DNS names. However, for Blob Storage, Traffic Manager at this point supports App Service, Cloud Service, or Public IP address end points, but not Storage end points, so the static website CNAME can only be mapped to one of the regions. If there’s a preference to work-around this, we can deploy an instance of App Service and use it to serve the static files for the website in each region, and these end points can be mapped to the Traffic Manager profile.
Cosmos DB – added “East US 2” as an additional write-enabled region for the Cosmos DB account used in this architecture. This means the Function apps deployed in each region can access its local instance of Cosmos DB, and Cosmos DB will take care of any data replication needed to maintain data integrity as a result of writes in any region.
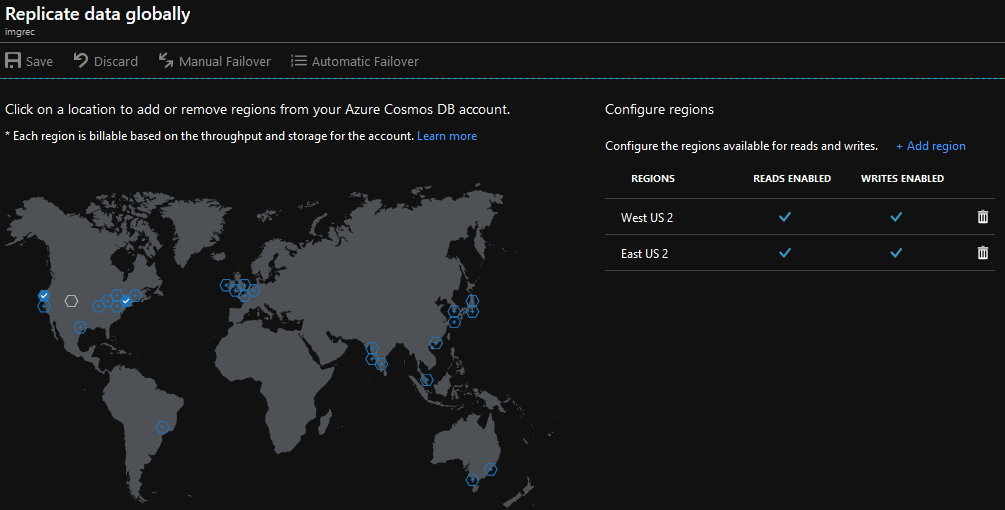
And that’s all we have to do for Cosmos DB; we don’t need to add logic to the application code to handle a fail-over scenario because Cosmos DB provides a top-level end point for applications to use (e.g., application clients use the “https://imgrec.documents.azure.com:443/” end point in this case, and Cosmos DB internally directs connections to the appropriate instances at “https://imgrec-westus2.documents.azure.com:443/” or “https://imgrec-eastus2.documents.azure.com:443/”).
It isn’t necessary to create more Cosmos DB instances, because Function app instances in separate regions can use a shared Cosmos DB instance. But, working with a Cosmos DB instance locally in the same region as the Function app instances yields better performance and provides fault-tolerance if/when region failures occur. Plus, Cosmos DB takes care of data replication across instances, which is the most complex part of this architecture.
Blob Storage – since we’re using RA-GRS (read-access geo-redundant storage), all files stored in Blob Storage will be available in the event of regional failures (even though read-only). Though the application needs some changes in order to use multiple Blob Storage regions, such as making sure the entire URL to each file stored is recorded along the metadata for each file in Cosmos DB (the original implementation assumes a single-region deployment but now image files can reside in either west or east region), so that the client application knows where to retrieve the file
Monitoring - now with a distributed architecture, Application Insights and Log Analytics also become shared (as opposed to regional) resources, like Traffic Manager. So the new resources should be configured to send diagnostics and application telemetry data to these resources, for centralized monitoring.
As a result, the resource group that hosts this application looks like this, now with the newly added resources in “East US 2” region:
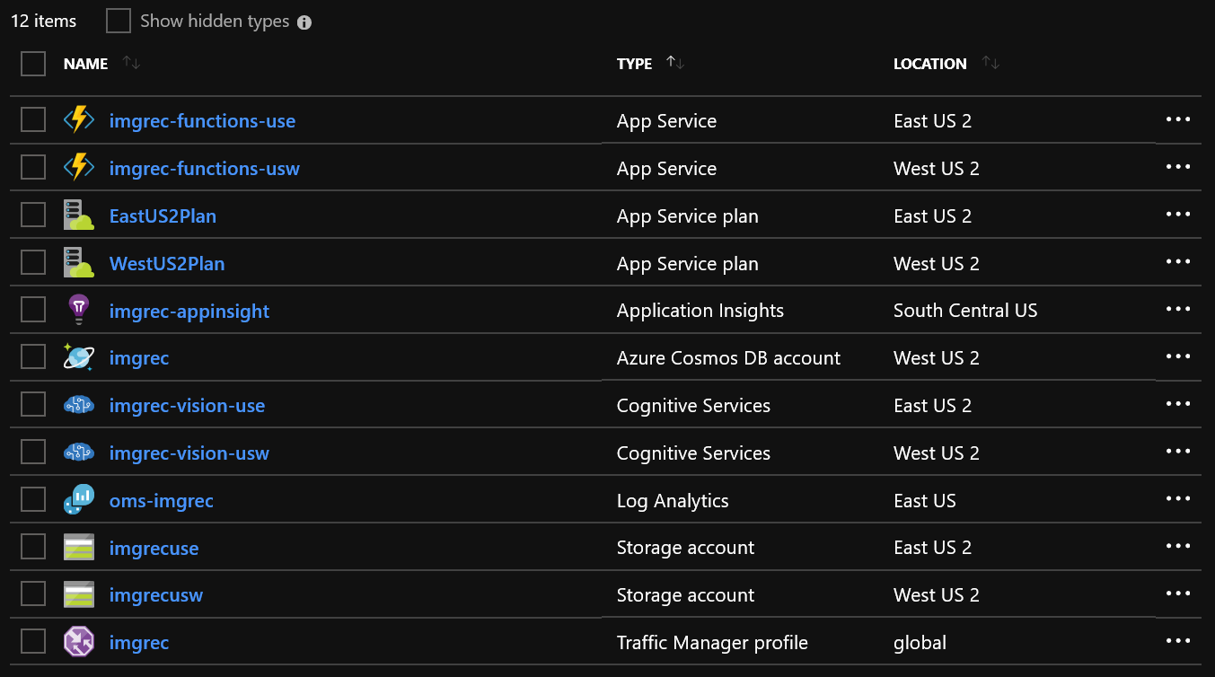
Finally, the configuration management, continuous deployment, logging and monitoring aspects mentioned earlier all help to quickly on-ramp additional regions in a consistent manner. If needed, this application can be provisioned in more regions across the world, to provide resources to customers closer to their locations, extending the production environment without disrupting live users. Each region scales independently, but works together seamlessly, leveraging Cosmos DB and its multi-master write capability to maintain data integrity across all regions.
A Few More Thoughts
Even if we provision this application across more regions across the world, such as two in Europe and two in Asia (6 regions total), this serverless architecture at idle state (no user transactions) has no running processes. It would only incur charges for the amount of storage consumed in Blob Storage (<1MB for the static web app files, plus images uploaded by users), and the Cosmos DB Request Unit (RU) throughput level allocation (and data storage consumed in Cosmos DB but that’s usually a smaller portion of the cost). We didn’t have to allocate and provision any persistent ‘servers’ to implement this architecture.
At the 400 RU/s level, each Cosmos DB instance costs approximately $50 per month (at list pricing published on the Azure website; rounded up for sake of looking at simpler numbers), and we’d incur that for each region provisioned for this architecture. Thus for this particular architecture with 2 regions provisioned, the minimal cost at idle would be (roughly) $100 per month. That is similar in cost to running two B1S Virtual Machine instances (B1S ‘burstable’ instance provides 1 Core, 1GiB RAM at $0.011/hour pay-as-you-go price level).
However, with this serverless implementation we are getting a highly available and resilient, fault-tolerant (active-active), highly scalable architecture with a globally distributed, multi-model database and storage solution. Cosmos DB with its multi-master write capability solves the most complex issue of maintaining a consistent database across multiple instances in different physical regions; the rest of the architecture is relatively simple and can all be maintained locally in each region. The cost plus effort would be significantly higher if a similar set of capabilities is implemented with Virtual Machine instances, even when using open-source software and application frameworks.
There is still a lot we can do to improve this implementation, such as adding security features, and a more robust and seamless user experience in case of region failures. The data in Cosmos DB is replicated to every region in a multi-master relationship, but we may need to think about partitioning in case the dataset may grow to a massive size. With RA-GRS storage the architecture ensures no data loss in case of region failures, and that Azure would seamlessly geo-failover to a secondary region while maintaining the same DNS entries for the Blob Storage service end points. However, in a geo-failover scenario, the data in the secondary region is read-only, so the application should handle this appropriately. In the case of this two-region implementation, roughly half of the image files would be read-only. So the application should present a different experience instead of throwing exceptions, when write operations are attempted in the secondary region in a geo-failover scenario.
Saving some of this work for another time. 😊