Cloud Computing and the Microsoft Platform
It has been a couple of months since I wrote about cloud computing and Microsoft’s plans and strategies. Now that Azure Services Platform has been unveiled at PDC2008, and after having the opportunities to discuss it with a community of architects from major enterprises and startups via the Architect Council series of events, I can talk about cloud computing from the perspective of the Microsoft platform, and the architectural considerations that influenced its design and direction.

Okay – cloud computing today is a really overloaded term, much more than SOA (service-oriented architecture) when it was the hottest ticket in IT. There are a lot of different perspectives on cloud computing, adding to the confusion and the hype. And unsurprisingly, there are a lot of confusion around Microsoft’s cloud platform too. So here is one way of looking at it.

Microsoft’s cloud includes SaaS (Software-as-a-Service) offerings as shown in the top row of the above diagram, such as Windows Live and the Business Productivity Online Suite; and the PaaS (Platform-as-a-Service) offering currently branded as the Azure Services Platform. For the rest of this article we will focus on the Azure Services Platform, as it represents a platform on top of which additional capabilities can be developed, deployed, and managed.
Comprehensive Software + Services Platform
At Microsoft, we believe that the advent of cloud computing does not necessitate that existing (or legacy) IT assets be moved into the cloud, as it makes more sense to extend to the cloud as opposed to migrate to the cloud. We think that eventually, a hybrid world of on-premise software and cloud-based services will be the majority norm, although the balancing point between the two extremes may vary greatly among organizations of all types and sizes. As a platform company, Microsoft’s intention is to provide a platform that can support the wide range of scenarios in that hybrid world, spanning the spectrum of choices between on-premises software and cloud-based services.
Thus Microsoft’s cloud platform, from this perspective, is not intended to replace the existing on-premises software products such as our suite of Windows Server products, but rather, completes the spectrum of choices and the capabilities required for a Software + Services model. Cloud Platform as a Next-Generation Internet-Scaled Application Environment So what is a cloud platform? It should provide an elastic compute environment that offers auto-scalability (small to massive), and ~100% availability. However, while some think that the compute environment means a server VM (virtual machine) allocation/provisioning facility that provides servers (i.e., Windows Servers, Linux Servers, Unix Servers, etc.) for administrators to deploy applications into, Microsoft’s approach with the Azure Services Platform is remarkably different.
Azure Services Platform is intended to be a platform to support a “new class of applications” – cloud applications.
On the other hand, the Azure Services Platform is not a different location to host our existing database-driven applications such as traditional ASP.NET web apps or third-party packaged applications deployed on Windows Server. Cloud applications are a different breed of applications. Now, the long-term roadmap does include capabilities to support Windows-Server-whichever-way-we-want-it, but I think the most interesting/innovative part is allowing us to architect and build cloud applications. To clarify, let us take a quick look at the range of options from an infrastructure perspective.
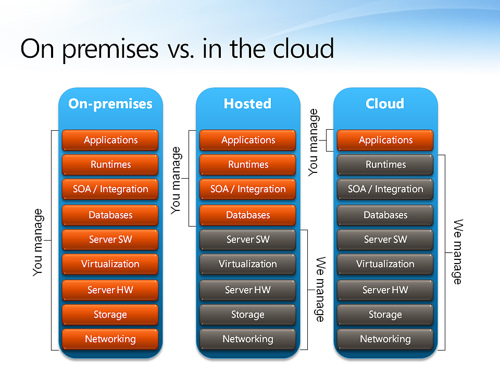
The diagram above provides a simplified/generalized view of choices we have from a hosting perspective:
- On-premises: represents the traditional model of purchasing/licensing and acquiring software, install them, and manage them in our own data centers
- Hosted: represents the co-location or managed outsourced hosting services. For example, GoGrid, Amazon EC2, etc.
- Cloud: represents cloud fabric that provides higher-level application containers and services. For example, Google App Engine, Amazon S3/SimpleDB/SQS, etc.
From this perspective, “Hosted” represents services that provide servers-at-my-will, but we will interact with the server instances directly, and manage them at the server level so we can configure them to meet our requirements, and install/deploy applications and software just as we have done with existing on-premises software assets. These service providers manage the underlying infrastructure so we only have to worry about our servers, but not the engineering and management efforts required to achieve auto-scale and constant availability.
“Cloud” moves the concerns even higher up the stack, where application teams only need to focus on managing the applications and specifying to the environment their security and management policies, and the cloud infrastructure will take care of everything else. These service providers manage the application runtimes, so we can focus on deploying and managing business capabilities, as well as higher-level and differentiating aspects such as user experience, information architecture, social communities, branding, etc.
However, this does not mean that any one of these application deployment/hosting models is inherently better than the other. Yep, while most people look at “hosted” and “cloud” models as described here, both as cloud platforms, they are not necessarily more relevant than the on-premises model for all scenarios. These options all present varying trade-offs that we as architects need to understand, in order to make prudent choices when evaluating how to adopt or adapt to the cloud.
Trade-Offs in the Cloud
Let us take a closer look at the trade-offs between the on-premises model and the cloud (as differences between “hosted” and “cloud” models are comparatively less).

At the highest level, we are looking at trade-offs between data consistency and scalability/availability. This is a fundamental difference between on-premises and cloud-based architectures, as “traditional” on-premises system architectures are optimized to provide near-real-time data consistency (sometimes at the cost of scalability and availability), whereas cloud-based architectures are optimized to provide scalability and availability (by compromising data consistency).
One way to look at this, for example, is how we used to design and build systems using on-premises technologies. We used pessimistic locking, optimistic locking, two-phase commit, etc., methods to ensure proper handling of updates to a database via multiple threads. And this focus on ensuring the accuracy and integrity of the data was deemed one of the most important aspects in modern IT architectures. However, data consistency is achieved by compromising concurrency. For example, in DBMS design, the lowest transaction isolation level “serializable” means all transactions occur in a serial manner (in a way, single-threaded) which promises safe updates from multiple clients. But that adversely impacts performance and scalability in highly concurrent systems. Raising the isolation level helps to improve concurrency, but the database loses some control over data integrity.
Furthermore, as we look at many of the Internet-scale applications, such as Amazon S3/SimpleDB, Google BigTable, and the open source Hadoop; their designs and approaches are very different from traditional on-premises RDBMS software. Their primary goal is to provide scalable and performant databases for extremely large data sets (lots of nodes and petabytes of data), which resulted in trading off some aspects of data integrity and required users to accommodate data that is “eventually consistent”.
Amazon Web Services CTO, Werner Vogels, has recently updated his thoughts on “eventual consistency” in highly distributed and massively scaled architectures. An excellent read for more details behind the fundamental principles that contribute to this trade-off between the two models.
Thus, on-premises and cloud-based architectures are optimized for different things. And that means on-premises platform are still relevant, for specific purposes, just as cloud-based architectures. We just need to understand the trade-offs so each can be used effectively for the right reasons.
For example, an online retailer’s product catalog and storefront applications, which are published/shareable data that need absolute availability, are prime candidates to be built as cloud applications. However, once a shopping cart goes into checkout, then that process can be brought back into the on-premise architecture integrated with systems that handle order processing and fulfillment, billing, inventory control, account management, etc., which demand data accuracy and integrity.
The Microsoft Platform
I hope it’s kind of clear why Microsoft took this direction in building out the Azure Services Platform. For example, the underlying technologies used to implement Azure include Windows Server 2008, but Microsoft decided to call the compute capability Windows Azure, because it represents application containers that operate at a higher level in the stack, instead of Windows Server VM instances for us to use directly. In fact, it actually required more engineering effort this way, but the end result is a platform that provides extreme scalability and availability, the transparency of highly distributed and replicated processes and data, while hiding the complexities of the systems automation and management operations on top of a network of globally distributed data centers. This should help clarify, at a high level, as to how Azure can be used to extend existing/legacy on-premise assets, instead of being just another outsourced managed hosting location.
Of course, this is only what this initial version of the platform looks like. From a long-term perspective, Microsoft does plan to increase parity between the on-premise and cloud-based platform components, especially from a development and programming model perspective, so that the applications can be more portable across the S+S spectrum. But the fundamental differences will still exist, which will help to articulate the distinct values provided by different parts of the platform.
Thus the Azure Services Platform is intended for a “new class of applications”. Different from the traditional on-premise database-driven applications, the new class of “cloud applications” are increasingly more “services-driven”, as applications operate in a service-oriented environment, where data can be managed and provisioned as services by cloud-based database service providers such as Amazon S3/SimpleDB, Google MapReduce/BigTable, Azure SQL Services, Windows Azure Storage Services, etc., and capabilities integrated from other services running in the Web, provisioned by various private and public clouds. This type of applications inherently operate on an Internet scale, and are designed with a different set of fundamentals such as eventual consistency, idempotent processes, federated identity, services-based functional partitioning and composition (loose-coupling), isolation, parallel and replicated data and process architecture, etc.
(originally published at https://blogs.msdn.microsoft.com/dachou/2009/01/13/cloud-computing-and-the-microsoft-platform/)